2019/08/20 hadoop伪分布式模型(03)
本文共 6803 字,大约阅读时间需要 22 分钟。

回顾:
Hadoop:存储和处理平台,两大类组件 hdfs:集群,NN 名称节点,SNN 辅助名称节点(实现HDFS日志与它的映像文件执行合并操作并且在HDFS的NN节点故障以后,能快速从image文件恢复元数据并等待个数据节点报告后生成一个完整的原数据列),DN 数据节点 mapreduce:(有中心节点的工作方式)集群,JobTracker(集群资源管理,作业管理),TaskTracker(负责运行作业,) 任务有两类:map, reduce
发展到hadoop2,mapreduce被切割了 YARN:只实现集群资源管理 RM集群资源管理器, NM节点管理器, AM 应用程序主节点 都运行在容器中,AM就是容器中的一个组件,AM可以根据需要去请求执行几个map任务,RM来选定几个NM来完成对应container的分配 可以实现NN节点的高可用
可以实现NN节点的高可用 Hadoop(2) 整个集群中只有一个RM,每个节点有一个NM 在1版本的时候hadoop整个集群都靠mapreduce框架来管理,mapred是一个1.开发API,2.运行框架。3.运行时开发模式 到了2版本,mapreduce只关心如何实现作业处理上,交给每个作业的,Application master来实现
Hadoop(2) 整个集群中只有一个RM,每个节点有一个NM 在1版本的时候hadoop整个集群都靠mapreduce框架来管理,mapred是一个1.开发API,2.运行框架。3.运行时开发模式 到了2版本,mapreduce只关心如何实现作业处理上,交给每个作业的,Application master来实现 单机模型:测试使用; 伪分布式模型:运行于单机;在单机上也是以集群方式运作的 分布式模型:集群模型
Hadoop,基于Java语言;jvm和java_home环境 jdk:1.6, 1.7, 1.8 hadoop-2.6.2 jdk 1.6+ hadoop-2.7 jdk 1.7+
https://hadoop.apache.org/old/
确保主机内存够大 编辑文件,提供javahome环境
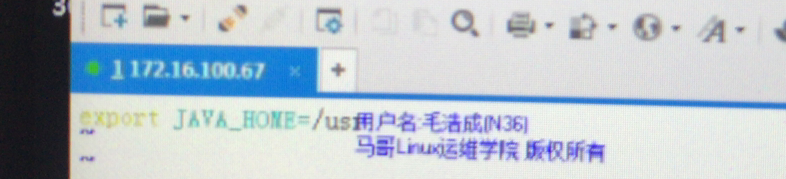


 任何java进程在运行起来以后,都会启动一个jvm进程,最需要配置堆内存(新生代,老年代,持久代)gc垃圾回收器 hadoop的NN就是一个jvm进程,到底应该启动以后使用多大的堆内存空间和gc,来通过hadoop_namenode_opts来配置
任何java进程在运行起来以后,都会启动一个jvm进程,最需要配置堆内存(新生代,老年代,持久代)gc垃圾回收器 hadoop的NN就是一个jvm进程,到底应该启动以后使用多大的堆内存空间和gc,来通过hadoop_namenode_opts来配置 这些不是必须的,测试主要前两者,一般定义hadoophome
这些不是必须的,测试主要前两者,一般定义hadoophome 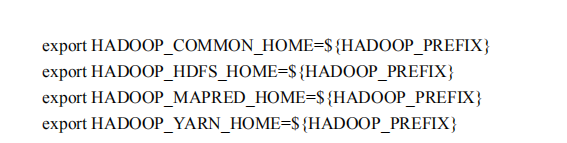
 hadoop安装路径
hadoop安装路径 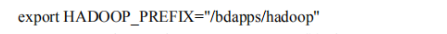 common组件的家目录
common组件的家目录  common是一个公共组件
common是一个公共组件  hdfs家目录通hadoop_prefix
hdfs家目录通hadoop_prefix 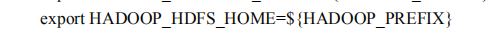 任何java程序用不到管理员的权限就不要用管理员的身份运行,ELS,LOGSTAH,TOMCAT,被劫持风险就大了, 所有创建三类程序,分别运行不同的组件 如果避免错误可以直接创建一个hadoop用户来使用
任何java程序用不到管理员的权限就不要用管理员的身份运行,ELS,LOGSTAH,TOMCAT,被劫持风险就大了, 所有创建三类程序,分别运行不同的组件 如果避免错误可以直接创建一个hadoop用户来使用 hadoop是一个分布式存储平台,分布式文件系统大多数运行的用户空间,最终文件还要存储在本地文件系统上,所有要正在本地文件系统上找个路径来存储数据
hadoop是一个分布式存储平台,分布式文件系统大多数运行的用户空间,最终文件还要存储在本地文件系统上,所有要正在本地文件系统上找个路径来存储数据 hadoop下的hdfs分别创建三个子目录,分别给三个角色存储数据 nn name node snn 辅助nn dn data node
hadoop下的hdfs分别创建三个子目录,分别给三个角色存储数据 nn name node snn 辅助nn dn data node  core-site 主站 全局配置
core-site 主站 全局配置 配置hdfs的
配置hdfs的 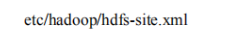
 **配置maper的,主要运行mapreduce任务的,am **
**配置maper的,主要运行mapreduce任务的,am ** 配置yarn的,核心框架,实行全局资源管理,rn nm
配置yarn的,核心框架,实行全局资源管理,rn nm
 设置堆内存的
设置堆内存的 指明从节点是什么,对于yarn来讲,每一个slave都是namenode,node manager=1.版本的task tracker节点
指明从节点是什么,对于yarn来讲,每一个slave都是namenode,node manager=1.版本的task tracker节点


 定义export hadoop 安装目录 path变量 yarn家目录
定义export hadoop 安装目录 path变量 yarn家目录 
 重读生效
重读生效 hadoop下的目录 bin目录是存放二进制文件的 hdfs是hdfs的管理程序的一个接口 mapered程序 hadoop整个hadoop的主程序 include头文件 lib 库文件 libexec可执行文件,可能会被主程序的其他程序所调用 sbin目录下的是脚本 启动控制集群的脚本 etc是配置文件目录,xml格式的文件是配置文件
hadoop下的目录 bin目录是存放二进制文件的 hdfs是hdfs的管理程序的一个接口 mapered程序 hadoop整个hadoop的主程序 include头文件 lib 库文件 libexec可执行文件,可能会被主程序的其他程序所调用 sbin目录下的是脚本 启动控制集群的脚本 etc是配置文件目录,xml格式的文件是配置文件
 创建用户,目录,属主属组也需要修改
创建用户,目录,属主属组也需要修改 进到安装目录,创建logs目录,让属组有写权限
进到安装目录,创建logs目录,让属组有写权限
 确保logs组有写权限
确保logs组有写权限 **整个hadoop运行模式都是在rpc运行框架运行的,伪分布式的主机地址肯定为localhost,默认namenode用的端口是8020 **
**整个hadoop运行模式都是在rpc运行框架运行的,伪分布式的主机地址肯定为localhost,默认namenode用的端口是8020 ** 保存在configuration当中 每个property’内部通常有两个属性,第一是name,第二个value是固定属性 名称和值
保存在configuration当中 每个property’内部通常有两个属性,第一是name,第二个value是固定属性 名称和值

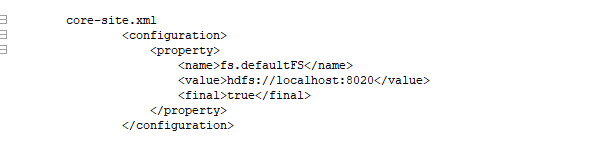 core-site.xml fs.defaultFS hdfs://localhost:8020 true
core-site.xml fs.defaultFS hdfs://localhost:8020 true  下一个专门定义hdfs的文件,hdfs的相关属性,复制因子就是副本数
下一个专门定义hdfs的文件,hdfs的相关属性,复制因子就是副本数 hdfs-site.xml dfs.replication hdfs副本数量 1复制数量 value为1 第二个property dfs.namenode.name.dir file:///data/hadoop/hdfs/nn存放位置 dfs.datanode.data.dir数据节点的数据目录 file:///data/hadoop/hdfs/dn fs.checkpoint.dir检查点文件 file:///data/hadoop/hdfs/snn fs.checkpoint.edits.dir检查点的编辑目录 file:///data/hadoop/hdfs/snn 不对hdfs写权限做严格检查
hdfs-site.xml dfs.replication hdfs副本数量 1复制数量 value为1 第二个property dfs.namenode.name.dir file:///data/hadoop/hdfs/nn存放位置 dfs.datanode.data.dir数据节点的数据目录 file:///data/hadoop/hdfs/dn fs.checkpoint.dir检查点文件 file:///data/hadoop/hdfs/snn fs.checkpoint.edits.dir检查点的编辑目录 file:///data/hadoop/hdfs/snn 不对hdfs写权限做严格检查

 hdfs-site.xml dfs.replication 1 dfs.namenode.name.dir file:///data/hadoop/hdfs/nn dfs.datanode.data.dir file:///data/hadoop/hdfs/dn fs.checkpoint.dir file:///data/hadoop/hdfs/snn fs.checkpoint.edits.dir file:///data/hadoop/hdfs/snn
hdfs-site.xml dfs.replication 1 dfs.namenode.name.dir file:///data/hadoop/hdfs/nn dfs.datanode.data.dir file:///data/hadoop/hdfs/dn fs.checkpoint.dir file:///data/hadoop/hdfs/snn fs.checkpoint.edits.dir file:///data/hadoop/hdfs/snn  配置集群的mapreduce framework,应该指定适用yarn,因为hadoop2.0的mapreduce运行在yarn上 local表示使用本地的,classic使用经典的mapreduce机制,此处必然 使用yarn
配置集群的mapreduce framework,应该指定适用yarn,因为hadoop2.0的mapreduce运行在yarn上 local表示使用本地的,classic使用经典的mapreduce机制,此处必然 使用yarn
 使用的framework是yarn,这个文件默认不存在,需要自己手动创建 mapred-site.xml mapreduce.framework.name yarn 配置yarn框架,scheduler调度器,不同的调度器对作业任务的调度方式是不尽相同
使用的framework是yarn,这个文件默认不存在,需要自己手动创建 mapred-site.xml mapreduce.framework.name yarn 配置yarn框架,scheduler调度器,不同的调度器对作业任务的调度方式是不尽相同  yarn-site.xml yarn.resourcemanager.address localhost:8032只是一个地址和端口 yarn.resourcemanager.scheduler.address localhost:8030 yarn.resourcemanager.resource-tracker.address localhost:8031 追踪器地址 yarn.resourcemanager.admin.address 管理地址 localhost:8033 yarn.resourcemanager.webapp.address web应用程序 localhost:8088 yarn.nodemanager.aux-services mapreduce_shuffleshuffle是一个辅助服务 yarn.nodemanager.auxservices.mapreduce_shuffle.class org.apache.hadoop.mapred.ShuffleHandler yarn.resourcemanager.scheduler.class调度器的类 org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler默认使用的CapacityScheduler调度器
yarn-site.xml yarn.resourcemanager.address localhost:8032只是一个地址和端口 yarn.resourcemanager.scheduler.address localhost:8030 yarn.resourcemanager.resource-tracker.address localhost:8031 追踪器地址 yarn.resourcemanager.admin.address 管理地址 localhost:8033 yarn.resourcemanager.webapp.address web应用程序 localhost:8088 yarn.nodemanager.aux-services mapreduce_shuffleshuffle是一个辅助服务 yarn.nodemanager.auxservices.mapreduce_shuffle.class org.apache.hadoop.mapred.ShuffleHandler yarn.resourcemanager.scheduler.class调度器的类 org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler默认使用的CapacityScheduler调度器 
 yarn-site.xml yarn.resourcemanager.address localhost:8032 yarn.resourcemanager.scheduler.address localhost:8030 yarn.resourcemanager.resource-tracker.address localhost:8031 yarn.resourcemanager.admin.address localhost:8033 yarn.resourcemanager.webapp.address localhost:8088 yarn.nodemanager.aux-services mapreduce_shuffle yarn.nodemanager.auxservices.mapreduce_shuffle.class org.apache.hadoop.mapred.ShuffleHandler yarn.resourcemanager.scheduler.class org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
yarn-site.xml yarn.resourcemanager.address localhost:8032 yarn.resourcemanager.scheduler.address localhost:8030 yarn.resourcemanager.resource-tracker.address localhost:8031 yarn.resourcemanager.admin.address localhost:8033 yarn.resourcemanager.webapp.address localhost:8088 yarn.nodemanager.aux-services mapreduce_shuffle yarn.nodemanager.auxservices.mapreduce_shuffle.class org.apache.hadoop.mapred.ShuffleHandler yarn.resourcemanager.scheduler.class org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler  jvm,dn,snn,nn,am必须指明堆内存大小,hadoop默认大小为1G
jvm,dn,snn,nn,am必须指明堆内存大小,hadoop默认大小为1G 定义你的hdfs的从节点列表

跑起来还需要格式化,做文件系统格式化
 格式化
格式化  运行程序的
运行程序的  启动一个dfs的管理客户端
启动一个dfs的管理客户端  做文件系统检测的
做文件系统检测的  mogoilfs有一个命令叫rebalance,重新均衡,这也是一个重新均衡程序,也就是移动数据副本的
mogoilfs有一个命令叫rebalance,重新均衡,这也是一个重新均衡程序,也就是移动数据副本的  运行dfs命令
运行dfs命令 http://hadoop.apache.org/docs/r2.6.5/配置文档列表非常清晰
http://hadoop.apache.org/docs/r2.6.5/配置文档列表非常清晰 hdfs命令有两类,用户命令http://hadoop.apache.org/docs/r2.6.5/hadoop-project-dist/hadoop-hdfs/HDFSCommands.html

 mv改名,rmr递归删除目录,du,put上传 使用格式 上传 dfs是你的hdfs或者hdoop的客户端工具 http://hadoop.apache.org/docs/r2.6.5/hadoop-project-dist/hadoop-common/FileSystemShell.html#put
mv改名,rmr递归删除目录,du,put上传 使用格式 上传 dfs是你的hdfs或者hdoop的客户端工具 http://hadoop.apache.org/docs/r2.6.5/hadoop-project-dist/hadoop-common/FileSystemShell.html#put 可以用url
可以用url 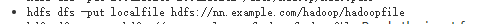
 格式化ok
格式化ok namenode会把内存中的元数据周期性写到持久存储当中,放的存储就是fsimage文件,不可能直接去编辑文件,保证变得更快,包括对文件的修改,会先放在一个checkpoint文件中, checkpoint的维护用snn来进行
namenode会把内存中的元数据周期性写到持久存储当中,放的存储就是fsimage文件,不可能直接去编辑文件,保证变得更快,包括对文件的修改,会先放在一个checkpoint文件中, checkpoint的维护用snn来进行 已经格式化成功了 现在试试上传文件
已经格式化成功了 现在试试上传文件 **hadoop有N个角色 datanode 数据节点 **
**hadoop有N个角色 datanode 数据节点 **  **以hdfs用户启动hdfs相关的进程 **
**以hdfs用户启动hdfs相关的进程 ** 以yarn用户启动yarn相关进程
以yarn用户启动yarn相关进程 先启动跟hdfs相关的,先启动名称节点 log真正的日志文件 jps jvm的ps命令,查看进程,-v详细信息,xmx对内存最大值,dhadoop.log.dir=日志的输出路径, 没有安装openjdk-devel包,jps命令是不存在的,因该是utils提供的
先启动跟hdfs相关的,先启动名称节点 log真正的日志文件 jps jvm的ps命令,查看进程,-v详细信息,xmx对内存最大值,dhadoop.log.dir=日志的输出路径, 没有安装openjdk-devel包,jps命令是不存在的,因该是utils提供的 现在启动第二个进程,启动辅助名称节点 snn,seccondary.namenode 虽然日志文件是out但是真正的文件是log
现在启动第二个进程,启动辅助名称节点 snn,seccondary.namenode 虽然日志文件是out但是真正的文件是log 第三部启动datanode
第三部启动datanode 上传文件,ls /查看跟下什么目录 mkdir创建目录http://hadoop.apache.org/docs/r2.6.5/hadoop-project-dist/hadoop-common/FileSystemShell.html#mkdir
上传文件,ls /查看跟下什么目录 mkdir创建目录http://hadoop.apache.org/docs/r2.6.5/hadoop-project-dist/hadoop-common/FileSystemShell.html#mkdir 属主hdfs,属组supergroup,不属于hadoop。意味之前定义hadoop组的用户是无法对目录写的
属主hdfs,属组supergroup,不属于hadoop。意味之前定义hadoop组的用户是无法对目录写的 所以就需要不要严格限制
所以就需要不要严格限制  上传目录,lsr递归显示目录=ls -
上传目录,lsr递归显示目录=ls - 
 dn是用来存数据的 current文件系统,但是要看还是要通过hdfs自己的接口
dn是用来存数据的 current文件系统,但是要看还是要通过hdfs自己的接口 也可以用本地文件系统访问,问题不大
也可以用本地文件系统访问,问题不大 文件是通过hdfs存放的,blk指的就是块的意思,块编号,因为是文本文件,所以切割以后也不会出错,所以在本地也可以看
文件是通过hdfs存放的,blk指的就是块的意思,块编号,因为是文本文件,所以切割以后也不会出错,所以在本地也可以看 可以在hdfs上看

 现在只启动了一个hdfs集群,还需要启动yarn集群 两个角色 resourcemanager nodemanager ,out真正日志文件是。log yarn用户只能看到自己启动的,hdfs的是看不到的
现在只启动了一个hdfs集群,还需要启动yarn集群 两个角色 resourcemanager nodemanager ,out真正日志文件是。log yarn用户只能看到自己启动的,hdfs的是看不到的 下面启动node manager 真正运行时,resourcemanager运行在主节点上,node manager在每个从节点上都运行起来
下面启动node manager 真正运行时,resourcemanager运行在主节点上,node manager在每个从节点上都运行起来
 **hdfs监听的端口是50020,90,70,75 8020.30,33,40,42,88 **
**hdfs监听的端口是50020,90,70,75 8020.30,33,40,42,88 ** 停止服务使用stop,dhfs和yarn rescoure manager 各自提供了一个web接口,通过接口可检查hdfs集群以及yarn集群的相关状态信息 hdfs 可以通过50070 所有地址,可以任意主机访问 yarn 的是8088,本地地址,只能默认访问localhost
停止服务使用stop,dhfs和yarn rescoure manager 各自提供了一个web接口,通过接口可检查hdfs集群以及yarn集群的相关状态信息 hdfs 可以通过50070 所有地址,可以任意主机访问 yarn 的是8088,本地地址,只能默认访问localhost
 集群id和块池都是自己生产的,BP=block pool
集群id和块池都是自己生产的,BP=block pool  summary,hdfs工作在什么特性下
summary,hdfs工作在什么特性下 安全功能关闭 cobores safemode安全模式关闭了 有三个文件和目录
安全功能关闭 cobores safemode安全模式关闭了 有三个文件和目录 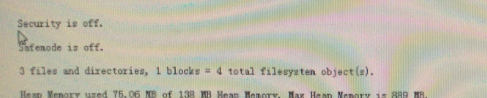 使用的百分比
使用的百分比 livenode 活着的节点
livenode 活着的节点 伪分布式模式只有一个
伪分布式模式只有一个 死亡节点
死亡节点 找不到的
找不到的 名称节点的日志状态 editlog放在,类似inoodb的事务日志文件要不断合并,fsimage文件由sentoryimage
名称节点的日志状态 editlog放在,类似inoodb的事务日志文件要不断合并,fsimage文件由sentoryimage 从name node取得,通过协议吧namenode上的,fsimage是真正可持久使用的文件,把当前版本的editlog取过来,取到secondary node机器上,把editlog合并成新版的fsimage,一旦合并好以后,新版的fsimage复制回去覆盖掉,新版 的editlog可能继续写着,把editlog复制过去,本地合并,更新版本,传回去,覆盖掉,secondary node帮助负责完成把edit log给合并在fs image上,保证尽可能多的当前节点所有的原数据信息,真正的元数据被当前节点一定是使用在内存中的, 类似(mysql的binlog,任何操作都只是追加)
从name node取得,通过协议吧namenode上的,fsimage是真正可持久使用的文件,把当前版本的editlog取过来,取到secondary node机器上,把editlog合并成新版的fsimage,一旦合并好以后,新版的fsimage复制回去覆盖掉,新版 的editlog可能继续写着,把editlog复制过去,本地合并,更新版本,传回去,覆盖掉,secondary node帮助负责完成把edit log给合并在fs image上,保证尽可能多的当前节点所有的原数据信息,真正的元数据被当前节点一定是使用在内存中的, 类似(mysql的binlog,任何操作都只是追加) editlog也不是完全都是经由追加定义的, 这就是hdfs的ui,yarn是监听在本地地址上 的
editlog也不是完全都是经由追加定义的, 这就是hdfs的ui,yarn是监听在本地地址上 的  在yarn上运行的程序有哪些
在yarn上运行的程序有哪些 node manager是相关的节点信息,监听在8042
node manager是相关的节点信息,监听在8042 **submit提交的作业,finished完成的作业,failed失败的作业,accepect接收的作业 **完成
**submit提交的作业,finished完成的作业,failed失败的作业,accepect接收的作业 **完成 tools集群的配置信息
tools集群的配置信息
 服务器的当前信息
服务器的当前信息 度量值,没启用
度量值,没启用 现在hadoop可以跑程序 了,mapreduce只是批处理作业, 还有hive,pig,spark,strom 应该有一个示例程序,examples,测试程序 运行的时候是以hdfs用户运行的 因为这个程序运行的时候要生成保存数据的,只有hdfs对hdfs文件系统才有写入权限,所以切换成hdfs调用yarn命令的子命令jar来运行
现在hadoop可以跑程序 了,mapreduce只是批处理作业, 还有hive,pig,spark,strom 应该有一个示例程序,examples,测试程序 运行的时候是以hdfs用户运行的 因为这个程序运行的时候要生成保存数据的,只有hdfs对hdfs文件系统才有写入权限,所以切换成hdfs调用yarn命令的子命令jar来运行
 有许多测试程序 aggregatewordcount 单词数统计。可以给文本文件做统计,各单词出现多少 pi最著名测试程序,求π的值 wordcout,基于mapreduce的方式来统计,in针对哪个或哪些文件,out统计以后输出保存在什么位置
有许多测试程序 aggregatewordcount 单词数统计。可以给文本文件做统计,各单词出现多少 pi最著名测试程序,求π的值 wordcout,基于mapreduce的方式来统计,in针对哪个或哪些文件,out统计以后输出保存在什么位置 map执行完是reduce任务
map执行完是reduce任务 reduce结果
reduce结果 查看输出的part文件
查看输出的part文件
转载地址:http://jjkgn.baihongyu.com/
你可能感兴趣的文章
java集合类(7)Stack
查看>>
7、深入分析java中的泛型机制
查看>>
java序列化机制之protobuf框架(快速高效跨语言)
查看>>
6-1 Book类的设计 (10分)
查看>>
7-3 学生类-构造函数 (15分)
查看>>
7-4 类的定义与对象使用 (15分)
查看>>
7-5 jmu-Java-03面向对象基础-02-构造函数与初始化块 (20分)
查看>>
6-1 数组工具类的设计 (16分)
查看>>
7-1 程序填空题2 (12分)
查看>>
7-2 程序改错题3 (12分)
查看>>
7-3 计算年龄 (20分)
查看>>
7-3 利用集合类排序 (12分)
查看>>
Swing开发之JComboBox篇
查看>>
JVM内存的设置(解决eclipse下out of memory问题)
查看>>
sscanf 总结
查看>>
android图片特效处理之图片叠加
查看>>
windows 使用GetLocalTime 和GetSystemTime 所获得的时间不同
查看>>
Android进阶2之图片缩略图(解决大图片溢出问题)
查看>>
Android学习笔记进阶19之给图片加边框
查看>>
Android学习笔记进阶18之画图并保存图片到本地
查看>>